Wrapper
O conceito de Tradutor do modelo foi imp,ementado no Integrate através
da interface
Wrapper.
Duas implementações desta interface são disponibilizadas pelo
Integrate:
WrapperJDBC
(para fontes de dados relacionais, utilizando um
driver JDBC
específico do SGBD desejado) e
WrapperCSV
(para acessar arquivos CSV). O Integrate utiliza uma instância de um
objeto que implementa esta interface para cada fonte de dados
disponível. As implementações disponibilizadas pelo Integrate funcionam
como um
proxy,
repassando as requisições para o
driver
real para que este acesse a fonte de dados.
A figura abaixo exibe a estrutura de classes definida pelo Integrate.
Para detalhes, consulte o
javadoc.
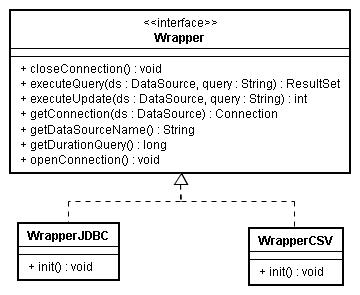
- closeConnection
- encerra a conexão com o SGBD
- executeQuery
- método que executa requisições de consulta no SGBD manipulado. Recebe
como argumento a fonte de dados que se deseja manipular,
encapsulada no javabean
da classe DataSource.
Outras opções serão disponibilizadas em versões futuras. O resultado é
retornado como um java.sql.ResultSet.
- executeUpdate
- método que executa requisições de atualização no SGBD manipulado.
Recebe como argumento a fonte de dados que se deseja
manipular, encapsulada no javabean
da classe DataSource.
Outras opções serão disponibilizadas em versões futuras. O resultado é
a quantidade de registros que foram alterados pela requisição. Vale
lembrar que os tradutores originais do Integrate agem como proxy, e apenas
repassam as requisições para o driver
JDBC e trata os resultados obtidos. Como o driver JDBC
original para arquivos CSV não
fazem operações de alteração, apenas de consulta.
Assim, o método executeUpdate()
da classe WrapperCSV
não tem limitações neste caso, a limitação é do driver JDBC.
- getConnection
- o funcionamento default
do Integrate torna transparente o acesso à fonte de dados, por não exigir do
mediador a necessidade de ter que manipulá-la diretamente. Porém, para
dar mais flexibilidade ao desenvolvedor do mediador, este método
possibilita que o mediador tenha acesso direto à um objeto do tipo java.sql.Connection,
caso ele opte por fazer os acessos diretos ao SGBD.
- getDataSourceName
- retorna o nome da fonte de dados relativa ao tradutor. Este nome é o
identificador registrado no arquivo integrate-datasources.xml.
- getDurationQuery
- retorna o tempo total de duração da última requisição executada. O
Integrate registra os tempos (em milisegundos) de início e de fim de
cada requisição. Se o usuário quiser saber o tempo total gasto, este
método faz o cálculo da diferença e retorna, funcionalidade que pode
ser útil durante o desenvolvimento do mediador ou durante a verificação
dos tempos gastos com o sistema em produção.
- openConnection
- inicia uma conexão com o SGBD, através do driver JDBC
registrado.
Novas implementações podem ser produzidas por
desenvolvedores JDBC para
atender suas necessidades, caso as disponibilizadas não sejam
suficientes.
Os tópicos abaixo exemplificam a utlização destas implementações,
através de alguns serviços disponibilizados pela da interface
ControllerI.
Para estes exemplos, supõem-se que os
arquivos
de configuração do Integrate estão corretamente definidos.
Consulta a
fonte de dados específica
Resultado de consulta
em XML
O método
executeQueryInXmlFormat()
executa uma consulta em uma fonte de
dados
específica, informando como argumentos o identificador da integração
desejada (devidamente definida no
integration.xml
) e
o comando SQL original desejado. O exemplo abaixo ilustra o uso deste
método:
1 ControllerI c = Controller.getInstance();
2 try {
3 StringBuilder s = c.executeQueryInXmlFormat("hsqldb",
4 "SELECT CODCLIENTE, NOME, SOBRENOME " +
5 "FROM CLIENTES");
6 c.stop("hsqldb");
7 System.out.println(s.toString());
8 } catch (Exception e){
9 (...)
10 }
Para
executar este método, o Integrate obtém as fontes de dados envolvidas
na integração informada (fonte de dados de origem e a(s) de destino) a
partir do identificador informado no argumento. Para cada
identificador de fonte de dados de destino, o Integrate verifica se não
é o mesmo da fonte de origem. se for, o Integrate apenas repassa a
consulta SQL. Se for diferente, o Integrate requisita do mediador a
consulta para a respectiva fonte de dados (ver
modelo estendido)
e este retorna a consulta convertida para a respectiva fonte de dados.
Ao receber a consulta convertida, o Integrate a repassa ao tradutor
para que este acesse a fonte de dados e obtenha os registros. Vale
lembrar que no estágio atual do
Integrate, o mediador necessita conhecer SQL e gerar as
consultas no formato conhecidos pela fonte de dados. Projetos futuros
devem abstrair este formato, eliminando esta necessidade.
Após
receber todos os registros, o Integrate novamente requisita o mediador
para integrar estes resultados. O resultado finalk é então formatado em
um objeto
java.text.StringBuilder,
cujo conteúdo contém os registros em formato XML. Um exemplo
do arquivo gerado pode ser visto abaixo:
<?xml version="1.0" encoding="UTF-8"?>
<results>
<result id=’hsqldb’>
<tuple>
<attribute name=’CODCLIENTE’>0</attribute>
<attribute name=’NOME’>ROGERIO</attribute>
<attribute name=’SOBRENOME’>ARANTES</attribute>
</tuple>
<tuple>
<attribute name=’CODCLIENTE’>1</attribute>
<attribute name=’NOME’>JOSÉ</attribute>
<attribute name=’SOBRENOME’>SILVA</attribute>
</tuple>
<tuple>
<attribute name=’CODCLIENTE’>2</attribute>
<attribute name=’NOME’>JOAO</attribute>
<attribute name=’SOBRENOME’>BATISTA</attribute>
</tuple>
</result>
</results>
Como pode ser visto no exemplo acima, o conteúdo gerado em XML contém
uma coleção de resultados, com um identificador da fonte de dados
utilizada (
tag
<id>,
que contém o mesmo identificador registrado na configuração do
Integrate). Cada resultado obtido contém uma coleção de linhas (ou
tuplas, identificadas pelas
tags
<tuple>),
e cada linha contendo uma coleção de colunas (
tags
<atribute>).
Consulta a
mais de uma fonte de dados
De maneira semelhante à exibida no exemplo anterior, pode-se consultar
mais de uma fonte de dados, bastando informar como argumento uma
coleção de identificadores de integrações e a coleção de suas
respectivas sentenças, algo como no trecho de código abaixo:
1 ControllerI c = Controller.getInstance();
2 try {
3 String[] idDataSources = {"csv", "hsqldb"};
4 String[] sql = {"SELECT CODINSTRUTOR, NOMEINSTRUTOR " +
5 "FROM DEPTO",
6 "SELECT CODCLIENTE, NOME, SOBRENOME " +
7 "FROM CLIENTES"};
8 StringBuilder s = c.executeQueryInXmlFormat(idDataSources, sql);
9 c.stop();
10 System.out.println(s.toString());
11 } catch (Exception e){
12 (...)
13 }
Como retorno do código acima, o Integrate gera o texto em formato XML
com os resultados separados por identificador, semelhante ao resultado
exibido acima, com dois conjuntos de
tags
<result>, cada um com seu respectivo
id.
Resultado de
consulta em arquivo
O Integrate também disponibiliza a impressão dos resultados em XML em
um arquivo texto. Os dois últimos exemplos exibidos acima podem ser
impressos em um arquivo através do método
saveResultSetsToXmlFile(). Como
argumento, deve-se informar o caminho e o nome do arquivo será
criado como saída e, caso o arquivo já exista, se o conteúdo obtido irá
sobrescrever o conteúdo existente ou se será adicionado ao
final.
Consulta
usando arquivo XML
Outra opção disponibilizada pelo Integrate é o fornecimento da
requisição através do método
executeQueryFile(),
que recebe como argumento um arquivo com formato pré-definido, além do
identificador da integração desejada. Este arquivo é devidamente
validado pelo
Integrate antes de ser processado. Abaixo, um exemplo do referido
arquivo:
<?xml version="1.0" encoding="UTF-8"?>
<query id="hsqldb_csv">
<target id="csv">
<sql>
SELECT CODINSTRUTOR, NOMEINSTRUTOR FROM DEPTO
</sql>
</target>
<target id="hsqldb">
<sql>
SELECT CODCLIENTE, NOME, SOBRENOME FROM CLIENTES
</sql>
</target>
</query>
Este arquivo contém uma coleção de fontes de dados de destino (
tags <target>),
cada qual com sua respectiva consulta SQL Este modelo ainda exige o
conhecimento de SQL por parte do mediador, mas novos formatos, com uma
abstração maior, serão
definidos em versões futuras do Integrate.
Manipulação de erros
O Integrate pode executar as operações citadas acima mesmo na
ocorrência de erros, de acordo com configurações feitas no arquivo
integrate-config.xml.
Suponha que o parâmetro
stopOnError esteja
definido como
true.
Se na execução do código que consulta mais de uma fonte de dados
exibido acima a primeira consulta tiver o nome da tabela errada, a
exceção é retornada à aplicação cliente, e todo o processo é
interrompido. Neste caso, a mensagem de erro gerada é impressa apenas
no arquivo de log padrão do Integrate (error.log). Já se o parâmetro
estiver definido como
false, o Integrate
gera o resultado final, imprimindo o erro no arquivo XML gerado, como
pode ser visto no exemplo abaixo:
<?xml version="1.0" encoding="UTF-8"?>
<results>
<result id=’csv’>
<errorMessage>
WrapperCSV: SQLException:
Cannot open data file ’testFiles/db-csv/DEPT.csv’ !
</errorMessage>
</result>
<result id=’hsqldb’>
<tuple>
<attribute name=’CODCLIENTE’>0</attribute>
<attribute name=’NOME’>ROGERIO</attribute>
<attribute name=’SOBRENOME’>ARANTES</attribute>
</tuple>
<tuple>
<attribute name=’CODCLIENTE’>1</attribute>
<attribute name=’NOME’>JOSÉ</attribute>
<attribute name=’SOBRENOME’>SILVA</attribute>
</tuple>
<tuple>
<attribute name=’CODCLIENTE’>2</attribute>
<attribute name=’NOME’>JOAO</attribute>
<attribute name=’SOBRENOME’>BATISTA</attribute>
</tuple>
</result>
</results>
Esta opção fornece flexibilidade ao Integrate, por não interromper todo
o processo de consulta, deixando a cargo da aplicação cliente (ou do
mediador) como melhor tratar este erro, sem desperdiçar o tempo de
processamento e os dados obtidos das outras fontes de dados.
Atualização nas fontes de dados
Como o Integrate age apenas como um
proxy entre a
aplicação cliente (ou o mediador) e a fonte de dados, teoricamente o
framework não
interfere na execução de sentenças SQL de alteração das fontes de
dados. A princípio, percebeu-se que comandos UPDATE podem ser
executados sem nenhuma limitação por parte do Controlador ou do
Tradutor, o que pode gerar alguma limitação seria do
driver JDBC que
efetivamente acessa a fonte de dados. Isso foi percebido durante os
testes efetuados com o
driver
JDBC para arquivos CSV disponibilizados pelo Integrate (como pode ser
visto
aqui).
Poucos testes foram efetuados neste sentido, mas algumas melhorias
foram detectadas, e devem ser introduzidas em versões futuras do
Integrate. Abaixo, citamos algumas:
- é necessário executar mais testes e tambem com outros
SGBD's, para confirmar que o Integrate não limita a execução
de alterações nas fontes de dados.
- o Integrate não implementa nenhum controle de transações.
Em situações onde uma requisição deve integrar mais de uma fonte de
dados, no caso de ocorrer alguma exceção com o framework
configurado para interromper a operação como um todo (ver arquivo integrate-config.xml),
o Integrate deveria garantir a atomicidade da operação, e desfazer as
alterações feitas com sucesso antes da exceção ser gerada (roolback).
Atualmente a execução das alterações é feita seqüencialmente, com o commit sendo
executado após cada acesso feito pelo respectivo Wrapper.
Se uma transação em uma fonte de dados efetivada com
sucesso for seguida de alguma exceção no acesso à fonte de
dados seguinte, o Integrate NÃO fará o rollback das
transações feitas com sucesso.
Integração sem
a alteração da aplicação cliente
O foco do Integrate está exatamente na integração de fonte de
dados sem a necessidade de alguma alteração na aplicação cliente, como
já discutido no conceito de
modelo estendido. A demonstraração esta funcionalidade está disponível através de um
exemplo.
Última atualização: 28/06/2009



